
How AI Neural Networks Show That the Mind Is Not the Brain
A series of simple diagrams shows that, while AI learns faster than the human brain, the human mind tackles problems that stump AIRecently, I’ve been arguing (here and here, for example) that we can use artificial neural networks (ANNs) to prove that the mind is not the brain. To recap, here is the logic of my argument:
Premise A: neural networks can learn better than the brain
Premise B: the human mind can learn better than a neural network
Conclusion: the human mind can learn better than the brain, therefore it is not the brain
This means if we can conclusively show the human mind can learn better than a neural network, then the mind is not the brain.
For Premise A, I’ve argued that the differentiable neural network is a superior learning model compared to the brain neuron’s “all or nothing principle”. The neural network has a “hot” or “cold” signal that it can learn from iteratively, whereas the neuron has a binary “yes” or “no” signal that does not allow for gradual improvement, making learning impossible for brain neurons.
This brings us to Premise B, where I will show that, nonetheless, the human mind can learn better than a neural network.
What test can show humans learn better than neural networks?
Let’s return to the original puzzle that Marvin Minsky (1927–2016) identified for the perceptron: learning the simple XOR function shown below. A simple perceptron fails this puzzle, but the XOR function can be learned, in a sense, with multiple layers of perceptrons, which we call an artificial neural network (ANN).
However, what is going on under the hood is quite messy and, as we shall see, that leads to a fundamental problem down the road.
Before we dive into all that, let’s look more closely at the XOR function and then consider what it means for a neural network to learn it.
Basic logic functions include AND, OR, and NOT. Logic functions are applied to logical variables, and we can represent them using truth tables.
Here is an example of the AND function on the two logic variables A and B in a truth table. T and F stand for True and False:
A | B | A AND B
F | F | F
T | F | F
F | T | F
T | T | T
The AND function should be true only when both A and B are true.
Although we don’t often stop to think about it, we all use this idea in everyday speech (which depends on logic). The sentence “Jane is a medical doctor and a lawyer” is True only if Jane is both a medical doctor and a lawyer. Thus, there are three ways that the sentence can be False and only one way that it can be True.
The logic table expresses this basic idea in logic. Thus, if we look at the table, we see there is only one T under the “A AND B” column: in the fourth row, where both A and B are T. In other words, the logic function A AND B can only be true when both A and B are true.
But now, let’s look at the truth table for the XOR function:
A | B | A XOR B
F | F | F
T | F | T
F | T | T
T | T | F
Examining the truth table, you’ll see that the “A XOR B” column is only true when either A or B is true but not when both are true. XOR stands for “exclusive or,” which means that A and B exclude each other. That’s why we only see the function register as True when either A or B is True, but not both at the same time.
For example, let’s say John and Harry are in a close race for Congress. Either could win (True) but both can’t win (False). Nor, under normal circumstances, can neither man win (False).
How did programmers get a neural network to learn the XOR function?
At first, it is not obvious. Marvin Minsky showed that a simple perceptron could not do it. That is because neural networks learn numbers, not logic. How can such a network be tweaked to learn a table of logic?
What if we replace logic with numbers so that the network doesn’t have to think, just add?
To get from here to there, we need a quick mind tweak: We represent True and False by the numbers 1 and 0. Hey presto! By representing logic as numbers, a neural network can now learn logic functions.
We can also draw the logic function on a 2D graph. Here is a 2D graph of the XOR function. You can see that it is divided into four quadrants, and the number 1 only shows up in a quadrant when one variable is 1 and the other is 0.
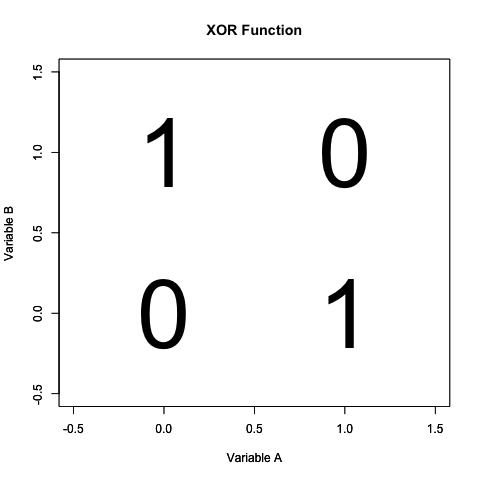
We can go one step further, and use colors. Let’s color 0 black, and 1 red. Now we have something that looks a bit like a checkerboard.

Now we finally reach the point where we can see a neural network learn the XOR function.
I won’t go into all the details of training the neural network here. There’s a great introduction to neural networks, in just 11 lines of Python: In fact, that is the code I used to produce this article.
So, I’ve got a neural network, and I am ready to train it on the XOR truth table we saw previously. The T and F are now replaced with 1 and 0:
A | B | A XOR B
0 | 0 | 0
1 | 0 | 1
0 | 1 | 1
1 | 1 | 0
I train the neural network on the XOR function, and get 100% prediction accuracy. But, what do the insides of a neural network look like? How is it making the predictions?
The great thing about a neural network is that we can peek inside its computational brain. Let’s do so.
You can think of the neural network as drawing lines on the 2D graph. The neural network designates points falling on one side of the line as True and points falling on the other side of the line as False. These different segments on the graph are called decision regions. Combining all the segments gives us a decision surface. This decision surface is the neural network’s brain.
So, now let’s see what the neural network decision surface looks like for the XOR problem:

Interesting, huh? You may be wondering how the neural network scores 100% accuracy when its decision surface doesn’t look at all like the XOR checkerboard.
The reason is that the neural network is trained only on the precise values of 0 and 1, while the decision surface itself includes all the numbers between 0 and 1. The neural network only needs to make a correct prediction for values of 0 and 1, not all the numbers in between. So it doesn’t matter what the decision surface looks like for the numbers in between.
While the neural network can make perfect predictions for the specific values, the fact that its decision surface does not look like the XOR checkerboard will lead to problems down the road. These problems will demonstrate that the human mind is not like a neural network.
What happens if we make the problem more complex?
Now for another mind tweak. Remember how the XOR function, imaged in 2D, looks like a piece of a checkerboard? What if we make the checkerboard bigger? Let’s extend the checkerboard graph so that it’s 8 × 8 squares, like a normal checkerboard:

As you might expect, to learn a bigger pattern, we need a more complex network. Now we start running into the problem: The network is too complex — and begins to get lost.
This is the fundamental stumbling block that keeps neural networks from reaching human level intelligence.
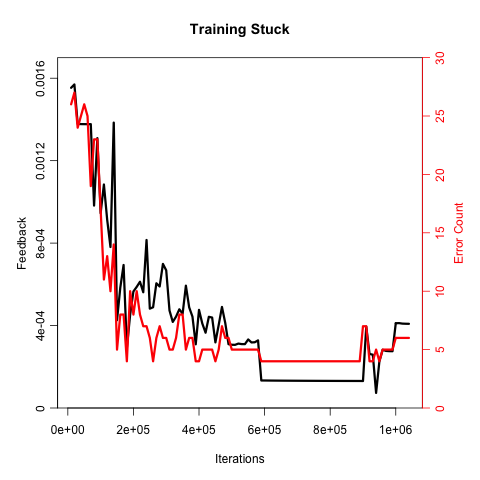
With the more complex setup, the network gets trained to a certain point, and then the training algorithm stops making progress. The problem is that the feedback points in multiple directions. Without a clear best direction, the training algorithm wanders around aimlessly.
Here’s an example where the training algorithm gets lost. We see that the feedback never goes to zero, but once the error level drops to a certain point, it stops getting better:
Let’s see this confused neural network’s decision surface:

As you can see the decision surface doesn’t look anything at all like the checkerboard. Yet, somehow it does correctly identify a significant portion of the squares.
To see why, we overlay the decision surface with the original checkerboard:

We can see that the decision surface does cover a large number of squares with the right color. But, it does this in a chaotic manner, like a piece of abstract art, not by following a pattern.
Because the neural network’s decision surface does not follow the checkerboard pattern to get its correct answers, the network becomes stuck in that configuration. It’s hard to make an incremental update towards the correct answer because the correct answer is so different.
This example shows that the human mind is doing something the neural network cannot do. When you look at the checkerboard you can almost immediately see the pattern. If one or two squares are removed, it is trivial for a human to figure out what fills in the blank. However, the neural network is unable to discover the underlying pattern.
Now here’s the clincher: The reason why the neural network cannot discover the pattern is precisely the same reason it is able to learn in the first place. As we discussed at the beginning, the neural network is able to learn because of the incremental updates. However, it is these same incremental updates that prevent the network from making the large leaps necessary to get it unstuck from its chaotic partial solutions.
And that is why neural networks cannot learn as well as the human mind. Neural networks do not really learn patterns, they incrementally move lines around to fit data. And these lines can end up fitting the data in a way that has nothing to do with the real pattern in the data. Humans, on the other hand, learn the pattern itself.
How does our experiment prove that the mind is not the brain?
To wrap things up, let’s revisit the logic of my argument.
Premise A: Neural networks can learn better than the brain
Premise B: The human mind can learn better than a neural network
Conclusion: The human mind can learn better than the brain, therefore it is not the brain
For premise A we saw that neurons are equivalent to multilayer perceptrons, which cannot learn due to the binary “yes” or “no” signal they rely on. By contrast, neural networks have a “hot” or “cold” signal that lets them learn incrementally. So the neural network can do something that the brain’s neurons are not structured to do, which is learn incrementally.
Now, for premise B, we see that it is precisely this incremental learning that prevents neural networks from performing at the level of the human mind — because the training gets stuck in partial solutions. And without incremental learning, algorithm-based learning is impossible.
Here is the fundamental dilemma, restated, that the neural network faces with regard to learning: If the training signal is not incremental, then it cannot learn. On the other hand, the incremental training leads the network to a point where it gets stuck, preventing it from learning the true pattern that generates the data.
In contrast, the human mind understands the checkerboard pattern and grasps the big picture immediately. This shows that the mind cannot be reduced to a neural network because it can do something the neural network cannot do.
Since the mind cannot be reduced to a neural network, and neural networks cannot be reduced to brain neurons, this leads us to the observation that the human mind is not the brain.
So, there we have it. Neural networks conclusively prove that the human mind is not the human brain.
Note: The featured photo is courtesy Michaela Murphy on Unsplash.
Here are the first two parts of my discussion of the question:
Artificial neural networks can show that the mind isn’t the brain Because artificial neural networks are a better version of the brain, whatever neural networks cannot do, the brain cannot do. The human mind can do tasks that an artificial neural network (ANN) cannot. Because the brain works like an ANN, the mind cannot just be what the brain does.
and
Can computer neural networks learn better than human neurons? They can and do; when artificial intelligence programmers stopped trying to copy the human neuron, they made much better progress. Humans can do things that AI cannot do, as we saw earlier, but those abilities are not due to the superior learning ability of a human neuron.