When AI Fails, the Results Are Sometimes Amusing. Sometimes Not.
Robert J. Marks, Justin Bui, and Samuel Haug examine five instances where AI went wrong, sometimes on the world stageEven if artificial general intelligence (AGI) could be achieved, a problem looms: The more complex a system is, the more can go wrong. If a computer could really match human thinking, a great deal could go wrong. In “When AI goes wrong” (podcast 160), Walter Bradley Center director Robert J. Marks is joined once again by members of his research group, Justin Bui and Samuel Haug, who is a PhD student in computer and electrical engineering. The topic is, what happens if AI starts behaving in bizarre and unpredictable ways?
A partial transcript and notes, Show Notes, and Additional Resources follow.
Robert J. Marks: Okay. I want to start out with Paul Harvey’s The Rest of the Story. Either Sam or Justin, have you ever heard of Paul Harvey?
Justin Bui: I have not.
Sam Haug: No, I have not.
Robert J. Marks: Okay. That shows I’m a senior citizen here. Paul Harvey had a series on the radio a very popular series. In fact, he wrote a couple of books too, where he recounted a sometimes familiar story and then added a little twist at the end — kind of an Alfred Hitchcock twist at the end, which few, if anyone, had ever heard about. The twist at the end was the rest of the story. It was a little elaboration that nobody expected.

We’re going to do that today with some popular AI stories. And the twist is going to be something that is not well known about how AI failed. These failures, called unexpected contingencies, are our “rest of the story.” It will illustrate some of shortcomings of AI and this idea of unexpected contingencies.
We’ll start out with some simple examples and then we’ll get into more serious cases involving human life. The list is from a peer reviewed paper that Sam and I wrote with Bill Dembski.
So let’s do the following. I’ll tell a story. And, Sam, I’d like you to give the rest of the story — give the story’s twist at the end.
First, Number One: Jeopardy is one of the most popular quiz shows in the history of television. Could AI win at Jeopardy? Well, it made big news. The answer is yes. In 2011, the world champions in Jeopardy? took on an IBM computer program named Watson. Watson didn’t respond to every answer correctly. It wasn’t designed to do so. But, in the end playing the game Jeopardy, Watson recorded a resounding win over both of these other Jeopardy champions and that made headlines. But people left out, maybe, a little quirk in Watson. So Sam what’s the next, what’s the rest of the story on This?
Sam Haug: Yes. So in this particular contest, there was quite a funny occurrence where Alex Trebek asked one of the contestants a question, and the answer that the human contestant gave was: “What” are “the Twenties” as the answer to that question — which was noted as incorrect by Trebek. And immediately afterwards Watson buzzed in and gave the exact same response: “What” are “the Twenties.” Obviously this answer was incorrect because it was just revealed to be incorrect. And this was something that the programmers of Watson did not foresee.
Robert J. Marks: Yeah, this was an unintended contingency. I imagine, when the Watson programmers heard this duplicate response, they facepalmed, and they go, “Oh my gosh, that was such an obvious thing we could have put into the software, but chose not to do.” Just fascinating.
Note: Another amusing Watson failure was an answer that placed Canada’s largest city, Toronto, in the United States. How that might have happened is explained here.
You know, Watson had great plans for itself in the field of medicine after it premiered on Jeopardy, but it failed. The idea was this: There are just hundreds and thousands of different papers published in the medical field. And wouldn’t it be wonderful if Watson could mine all of this data! Based on a query from a physician who gave symptoms and details about the case, to respond with a list of papers relevant to what was happening. This would save the doctor from wading through thousands of papers in the literature.
Watson contracted with medical research group and hospital, MD Anderson. But after a while, MD Anderson just fired Watson. It just wasn’t doing the job. And in fact, we listed this as Number One in the top 10 AI exaggerations, hyperbole and failures in the year 2018. Since then, IBM Watson’s application expectations have even fallen further. And so we’re not sure what’s in the future for Watson. But we can see that even though it was working well, it did have these unintended contingencies.
It got ugly, actually, between Watson and MD Anderson:
Houston’s MD Anderson Cancer Center began employing Watson in 2013, accompanied by great hope and fanfare. A story headlined, “IBM supercomputer goes to work at MD Anderson,” began,
“First he won on Jeopardy!, now he’s going to try to beat leukemia. The University of Texas MD Anderson Cancer Center announced Friday that it will deploy Watson, IBM’s famed cognitive computing system, to help eradicate cancer.”
The idea was that Watson would analyze enormous amounts of patient data, looking for clues to help in diagnosis and recommend treatments for cancer patients based on the research papers in its database and the patterns it discovered through data mining.
Five years and $60 million later, MD Anderson fired Watson after “multiple examples of unsafe and incorrect treatment recommendations.” Internal IBM documents recounted the blunt comments of a doctor at Jupiter Hospital in Florida: “This product is a piece of s—.… We can’t use it for most cases.”
IBM spent more than $15 billion on Dr. Watson with no peer-reviewed evidence that it improved patient health outcomes. Watson Health has disappointed so soundly that IBM is now looking for someone to take it off their hands.
– Gary Smith, Mind Matters News (March 29, 2021)
Robert J. Marks: Example Number Two has to do with another piece of IBM software in 1997. IBM’s Deep Blue software beat world champion Gary Kasparov at chess. This made world headlines. One of Deep Blue’s moves was particularly curious; the unexpected move, psychologically, threw Kasparov off his game. And he lost.
Kasparov looked at the move and said, I can see no reason for why, IBM Deep Blue made this particular move and it blew him all off his game. Psychologically.
One of the chess experts who were commenting about the game said, quote, It was an incredibly refined move of defending while ahead, to cut off any hint of counter moves. Well, you know, I guess skill in a game is like interpreting art in a painting. Some people will look at a painting and will think this is great art. And others will say, this looks like a kid’s finger painting. And that was indeed the case for this incredibly educated commentator. So the interesting thing is, what is the rest of the story? So Sam, could you, could you kind of finish this out? What’s the little twist on this Deep Blue move?
Sam Haug: Yes. This one’s also a little humorous. Over a decade after this match, one of the computer scientists who designed Deep Blue, Murray Campbell, confessed that the move that Deep Blue made that threw Kasparov off his game was a random move that Deep Blue had chosen because Deep Blue was unable to choose a good move. And so he just chose one at random.
Robert J. Marks: Yeah, that’s fascinating. I think one of the quotes from Murray was that Kasparov had concluded that the counter-intuitive play must be a sign of superior intelligence. He had never considered that it was simply a bug in the code.
The story is told in some detail here: One of Deep Blue’s designers has said that when a glitch prevented the computer from selecting one of the moves it had analysed, it instead made a random move that Kasparov misinterpreted as a deeper strategy.
He managed to win the game and the bug was fixed for the second round. But the world champion was supposedly so shaken by what he saw as the machine’s superior intelligence that he was unable to recover his composure and played too cautiously from then on. He even missed the chance to come back from the open file tactic when Deep Blue made a “terrible blunder”.
… He over-thought some of the machine’s moves and became unecessarily anxious about its abilities, making errors that ultimately led to his defeat. Deep Blue didn’t possess anything like the artificial intelligence techniques that today have helped computers win at far more complex games, such as Go. –
Mark Robert Anderson, The Conversation, (May 11, 2017)
Robert J. Marks: Okay. Third story: A deep convolutional neural network was trained to detect wolves. Now, deep convolutional neural networks do make mistakes in their classification; that’s just the way that it works. But this one incorrectly classified a Husky dog as a wolf. So the designers of the code went in and did some forensics and they found out that this was a fluke of the neural network. What happened here, Sam? What was the rest of the story?
Sam Haug: The neural network in this particular instance had not been training on the features of the animals that it was classifying. It was picking up on the fact that all of the wolf pictures it was fed as training data had snow in the background and all of the dog pictures it was given as training data did not have snow. So the neural network had not learned anything about the features of these animals; it had just learned to detect the presence of snow.
Robert J. Marks: That is really incredible. Justin, have you found out that this can happen in deep convolutional neural networks? Have you ever bumped across it?
Justin Bui: Yeah. It it’s pretty comical when you see things like that. It kind of goes hand in hand with how the network’s developed and, and how it’s trained. You know, it takes some very careful thought and preparation to not only design a neural network but to train it. In fact, you know, it’s, it’s often said that 90% of a system’s value is in it’s training and input data. Data is everything; garbage in equals garbage out.

And it’s funny, I chuckle when I hear about that story. But you know, just for, for kicks a couple weeks ago, I built a simple little convolution neural network to classify cats and dogs. It did so with really good accuracy, in the order of like 97, 98%. And then, for last, I fed it a piece of fruit.
I fed it an image of a kumquat. And, yeah, it turns out kumquats are a lot like dogs, apparently. So there’s just some oddities, some peculiarities that go into developing these systems. And again, it’s garbage in, garbage out. And if you’re not thinking about some of these contingencies, you may never come across them.
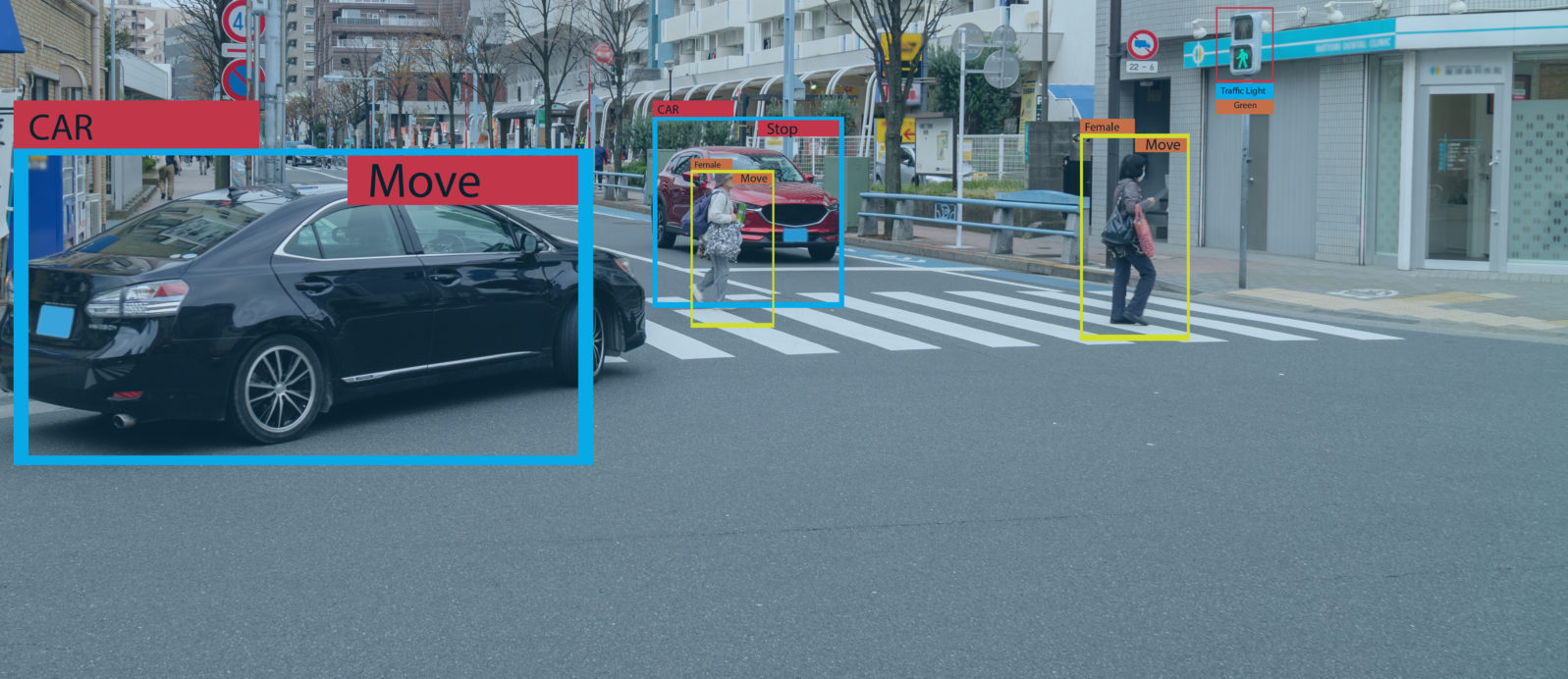
Robert J. Marks: That’s incredible. Okay. Thank you. Story Number Four: Self-driving cars are still under development and, despite promises, are still very far away from Level Five, doing what a human can do. So self-driving cars in early development were trained to watch out for things like pedestrians, deer, and road debris. You don’t want to hit a pedestrian. You don’t want to hit a deer. You don’t want to run over road debris. This worked out most of the time, but there were some serious flaws, at least in this early development. So Sam, what’s the rest of the story here?
Sam Haug: A very serious side effect happened in 2018. An Uber self-driving car in Tempe, Arizona actually struck and killed a pedestrian because it was unable to correctly classify this pedestrian as a pedestrian and as such did nothing to avoid the collision. One of the engineers that worked on this self-driving car thinks that the vehicle was able to see the pedestrian, but that it was not able to correctly identify it and avoid it. And it’s just a very sad occurrence of an unexpected contingency.
Note: “Unanticipated consequences will always be a problem for totally autonomous AI. Windblown plastic bags are the urban equivalent of the tumbleweed. A self-driving car mistakes a flying bag for a deer and swerves to miss it. After making this mistake, the AI can be adapted so as to not repeat this particular mistake. The problem, of course, is that all such contingencies cannot be anticipated. As a result, totally autonomous self-driving cars will always be put into situations where they will kill people.
“Should totally autonomous cars be banned? The answer depends on how many people they kill. Human-driven vehicles have never been outlawed because human drivers kill. So totally autonomous self-driving cars might be adopted for mainstream use when they kill significantly fewer people on average than human-driven vehicles.” –
Robert J. Marks, Mind Matters News, (February 22, 2019)
 Self-driving cars futurist landscape
Self-driving cars futurist landscapeRobert J. Marks: So I think the bottom line here is when AI involves human life and the potential death of a human being, you have to be very careful about unintended contingencies… We still have hope that this artificial intelligence that caused this death of this pedestrian in the Uber self-driving car and be corrected, but still, this was a terrible unintended contingency. And they remained a, major obstacle in the development of Level Five self-driving cars. Justin, do you have any comments on this?
Justin Bui: I think the self-driving nature of cars is still quite a ways away. There’s a lot of systems out there that can reasonably identify pretty much every road hazard with a high level of confidence. But when it comes to human life, it’s one of those things that even a 3–4% chance of misclassification is catastrophic. So I think a lot more due diligence needs to be paid to classification and detection systems. And, and it’s something that I think it’s just going to take some time to tackle.

Robert J. Marks: Yeah. And, you know, Tesla keeps coming out with all these press releases that they are doing great things — and they clearly are doing great things. One of our writers at Mind Matters News, Jonathan Bartlett, comments extensively on Tesla’s updates.
And I’ve talked to some people with some Tesla self-driving cars. They can take their hands off the steering wheel for a while but Tesla will warn them after a while. It says, you know, your hands haven’t been on the steering wheel for a while. Let’s see them. And so they’re not ready to go to totally autonomous self-driving cars as of yet.
Okay. Here is the fifth story — and the stories are getting more and more serious. We started out with little things like Jeopardy having IBM Watson, repeat an answer. That was, a little curious thing but we just got done with talking about how Uber, the self-driving car, could kill people.
And now we’re going to get to something which is very serious. A complex system could have caused millions of deaths. Let me give you the story. During the height of the the Cold War (1946–1991), the U.S and the Soviet Union were on the political knife edge of something called mutually assured destruction or M.A.D. The idea was is that if the United States blew up the Soviet Union, then the Soviet Union would blow up the United States. And both of the countries would be flat and glow in the dark.
In order to play this terrible game a little bit more intelligently the Soviets deployed a satellite early warning system called O.K.O to watch for in missiles fired from the United States. On September 26, 1983, O.K.O detected incoming missiles.
At a military base outside of Moscow, sirens blared. The Soviet brass was told by O.K.O to launch a thermo-nuclear counterstrike against the United States. Doing so would result in millions being killed. The officer in charge, Lieutenant Colonel Stanislav Petrov, looked at these incoming missiles and he felt that something was fishy. It just didn’t feel right. The United States would not launch a preemptive strike doing this sort of strategy.
So after informing his superiors of his hunch, that O.K.O was not operating correctly, Petrov did not obey the O.K.O order. Upon further investigation. O.K.O was found to have mistakenly interpreted sun reflecting off of clouds as incoming U.S. missiles. In other words, these signals were simply the sun reflecting off of clouds. There was no U.S. missile attack and Petrov’s skepticism of O.K.O’s alarm may have saved millions of lives.
Robert J. Marks: So we’ve gone from the very innocent to the very serious in what happens with AI unintended contingencies. Unexpected contingencies from complex AI can become more and more serious as we’ve seen.
I don’t know about you guys, but I play Alexa. And when you can’t get Alexa to play a song you want, it’s annoying, but it doesn’t cost any human lives. On the other end of the spectrum, killer self-driving cars and detectors of thermonuclear strikes can’t be allowed to make mistakes if they do lives will be lost.
In the examples that Sam and I have gone through, we, we have run the gamut from the very innocent to the very serious. The name of the paper in which this is outlined is Exponential Contingency Explosion (Implications for Artificial General Intelligence). It’s by Sam, design theorist William Dembski and me and it appears in the peer-reviewed AI journal, IEEE Transactions on Systems, Man, and Cybernetics (2021) — and Sam is the first author.
Now in that paper, we also do a bit of math. We show that the number of contingencies can increase exponentially with respect to the system complexity. The number of contingencies can become so numerous that they cannot all be looked at individually. This is troubling. This is not good news for AGI, which by its very nature must be very complex.
Next: As complexity increases linearly, contingency increases exponentially. Put another way, complexity adds up but its problems multiply.
Here’s are Parts 1 and 2 of Episode 159, featuring Robert J. Marks and Justin Bui: If not Hal or Skynet, what’s really happening in AI today? Justin Bui talks with Robert J. Marks about the remarkable AI software resources that are free to download and use. Free AI software means that much more innovation now depends on who gets to the finish line first. Marks and Bui think that will spark creative competition.
and
Have a software design idea? Kaggle could help it happen for free. Okay, not exactly. You have to do the work. But maybe you don’t have to invent the software. Computer engineer Justin Bui discourages “keyboard engineering” (trying to do it all yourself). Chances are, many solutions already exist at open source venues.
In Episode 160, Sam Haug joined Dr. Marks and Dr. Bui for a look at what happens when AI fails. Sometimes the results are sometimes amusing. Sometimes not. They look at five instances, from famous but trivial right up to one that nearly ended the world as we know it. As AI grows more complex, risks grow too.
In Episode 161, Part 1, Marks, Haug, and Bui discuss the Iron Law of Complexity: Complexity adds but its problems multiply. That’s why more complexity doesn’t mean more things will go right; without planning, it means the exact opposite. They also discuss how programmers can use domain expertise to reduce the numbers of errors and false starts.
and
In Part 2 of Episode 161, they look at the Pareto tradeoff and the knowns and unknowns:
Navigating the knowns and the unknowns, computer engineers must choose between levels of cost and risk against a background with some uncertainty. Constraints underlie any engineering design — even the human body.
Show Notes
- 00:37 | Introducing Justin Bui and Samuel Haug
- 01:18 | The Rest of the Story
- 02:50 | Could AI Win at Jeopardy?
- 05:39 | IBM’s Deep Blue
- 07:52 | Deep Convolutional Neural Network
- 10:31 | Self-Driving Cars
- 16:33 | Unexpected Contingencies
Additional Resources
- Haug, Samuel, Robert J. Marks, and William A. Dembski. “Exponential Contingency Explosion: Implications for Artificial General Intelligence.” IEEE Transactions on Systems, Man, and Cybernetics: Systems (2021).
- Robert J. Marks II, This Year’s (2018’s) Top Ten AI Exaggerations, Hyperbole, and Failures: Part II, Mind Matters News
- Lauren Vespoli, Where Watson went wrong, MM&M, Sept 8, 2021
- Paul Scharre. Army of none: Autonomous weapons and the future of war. WW Norton & Company, 2018.