
Can AI Really Know When It Shouldn’t Be Trusted?
Some researchers claim to have taught AI how to recognize its own untrustworthiness. Others say that’s impossibleRecently, we were told that artificial intelligence is now smart enough to know when it can’t be trusted:
How might The Terminator have played out if Skynet had decided it probably wasn’t responsible enough to hold the keys to the entire US nuclear arsenal? As it turns out, scientists may just have saved us from such a future AI-led apocalypse, by creating neural networks that know when they’re untrustworthy.
David Nield, “Artificial Intelligence Is Now Smart Enough to Know When It Can’t Be Trusted” at ScienceAlert (November 25, 2020)
That’s a big claim. Intelligent humans often can’t know when they are untrustworthy.
These deep learning neural networks are designed to mimic the human brain by weighing up a multitude of factors in balance with each other, spotting patterns in masses of data that humans don’t have the capacity to analyse.
David Nield, “Artificial Intelligence Is Now Smart Enough to Know When It Can’t Be Trusted” at ScienceAlert (November 25, 2020) The paper is open access.
But how do computer scientists give the machine a quality they may not understand or recognize themselves?
We put the question to computer mavens Jonathan Bartlett and Eric Holloway.
Bartlett’s response was straightforward: “Wow. That’s ridiculous. The summary statement is so far from what they did, it’s hard to even see the connection, except by abusing words.”
He went on to explain what the computer scientists really did. He writes,
They incorporated statistical error into a neural network. Normally, neural networks only report a value and you just accept it. Someone made a neural network that posted something more akin to a statistical probability. Basically, if the input is an outlier (outside or on the far edges of the training data), then the neural network has a less of a chance of being right. So it tells you that. This was not impossible to do before; it just took more processing power. They came up with a way to do it faster.
It has no actual connection to “untrustworthiness” in the sense of “Is the NN going to decide to be mean to us?”.
If you basically re-read the article without the first two paragraphs, it is a reasonable article. The first two paragraphs are super-amped-up hype that seems to actually miss the meaning of the article.
Indeed. Further down in the media release for the paper, we read:
The research team compares it to a self-driving car having different levels of certainty about whether to proceed through a junction or whether to wait, just in case, if the neural network is less confident in its predictions. The confidence rating even includes tips for getting the rating higher (by tweaking the network or the input data, for instance).
While similar safeguards have been built into neural networks before, what sets this one apart is the speed at which it works, without excessive computing demands – it can be completed in one run through the network, rather than several, with a confidence level outputted at the same time as a decision.
David Nield, “Artificial Intelligence Is Now Smart Enough to Know When It Can’t Be Trusted” at ScienceAlert (November 25, 2020)
So the real advance was incorporating statistical certainty checks without adding significantly to the demand for computing power. A very helpful development, sure, but… SkyNet?
Could AI come to recognize its own limitations? Eric Holloway notes that the idea contradicts basic principles of what AI is and how it works: “The headline contradicts a fundamental theorem known as Rice’s theorem, which states that computers cannot, in general, know any non-trivial property about themselves, which includes trustworthiness.”
“A second problem is the headline does not imply the converse, whether AI can know when it can be trusted. This contradicts Gödel’s second incompleteness theorem, which is that computers cannot prove that their proofs are reliable.”
“Finally, this research doesn’t address the well-known flaw in deep learning systems that they are very susceptible to ‘adversarial examples’: examples that are tweaked to fool AI systems such that the AI is completely certain about its drastically incorrect prediction.”
Here’s an adversarial example from OpenAI:
Adversarial examples are inputs to machine learning models that an attacker has intentionally designed to cause the model to make a mistake; they’re like optical illusions for machines. In this post we’ll show how adversarial examples work across different mediums, and will discuss why securing systems against them can be difficult …
To get an idea of what adversarial examples look like, consider this demonstration from Explaining and Harnessing Adversarial Examples: starting with an image of a panda, the attacker adds a small perturbation that has been calculated to make the image be recognized as a gibbon with high confidence.
Ian Good fellow, Nicolas Paper not, Sandy Huang, Rocky Duan, Pieter Abbeel, Jack Clark, “Attacking Machine Learning with Adversarial Examples” at OpenAI (February 24, 2017)
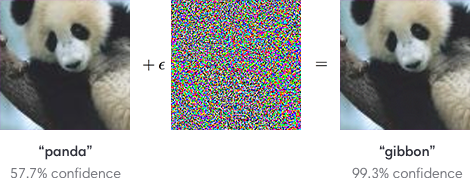
So, with a small disturbance, the machine was much more confident that the creature pictured here was a gibbon than a panda… This paper offers more information and examples.
So it looks like the machine that corrects its own errors is right up there with the machine that knows what we really want even when we mistakenly ask for something else… Not in this universe. Not anytime soon anyway.
You may also enjoy: The Top Ten AI hypes of 2018 and Top Ten AI hypes of 2019.