
Machine Intelligence and Reasoning: We Are Not on a Path to AGI
AI guru François Chollet’s Abstraction and Reasoning Corpus (ARC) proves we’re not on a path to AGITo understand why we are not, we would do well to look at Chollet’s ARC test.
Michael Spencer publishes the Artificial Intelligence Report, with over 237,000 subscribers and counting. I made his list of “who to follow” in AI this year. I am very grateful for that and I like his motto that “we don’t just learn from topics, we learn from people.”
July 16, he published on LinkedIn an article highlighting machine learning legend François Chollet reasoning test for LLMs (I quote Chollet in my book. Among other achievements, he created the Keras deep learning library, released in 2015 and used by over 2.5M developers to date ). In 2019 Chollet released the Abstraction and Reasoning Corpus (ARC) as a benchmark to test the intelligence of AI.
The Strawberry Project
The full article, by Spencer and Jurgen Gravestein, is well worth reading. It addresses OpenAI’s secretive “Strawberry” project claiming next generation reasoning capabilities and the ability to perform “deep research” from the still under wraps GPT-based technology. It begins
OpenAI rolls out Strawberry fields of AGI 🍓
Hello Everyone, Welcome to our next article in our AGI series. In it we explore what AGI means and how we might know when we get there. It’s not always clear what Sam Altman has had in his kool-aid o…
OpenAI is working with a 5 level framework similar to the scale adopted by self-driving car researchers. On such a scale, 1 is the lowest capability and 5 is fully autonomous driving (go to sleep in the back seat if you wish). For LLMs, OpenAI distinguishes steps toward full AGI as follows:

Today’s models, like GPT-4o are pegged at Level 1, according to OpenAI. Project Strawberry is intended to produce AI that can reason, achieving Level 2 or “somewhere between Level 1 and Level 2.”
But as Spencer points out, it seems like progress is slowing. Claims made by OpenAI and other foundational model makers sounded more promising and impressive last year. Not so surprising.
What the ARC test does
Fast forward to Chollet’s pesky ARC test. What I zeroed in on is that most of the problems offered can be solved by a five year old, while OpenAI is touting Strawberry as having the intelligence of a “Ph.D.”
Hmmm. Confusion about “intelligence” here? I think so. The other important takeaway is that ARC is kept entirely private, so the LLM can’t have memorized any of it. It is not widely appreciated that much of ChatGPT’s and other LLMs’ impressive performance is due to hoovering up many of the answers in training.
Think of the sheer volume of code, blogs, tweets, articles, Wikipedia entries, poems, rants, and all else on the web today. This alone is mind boggling complexity. Given Moore’s Law (and NVIDIA!) and power grids for terawatt hours of energy, a deep-pocketed company can now capture much of this text, image, and sound in training. Many times, the LLM is not actually answering your question but a similar (or identical) question someone already asked on the web somewhere. This, among other factors, helps explain the terrible performance of all LLMs on Chollet’s ARC corpus to date:
Commonsense knowledge
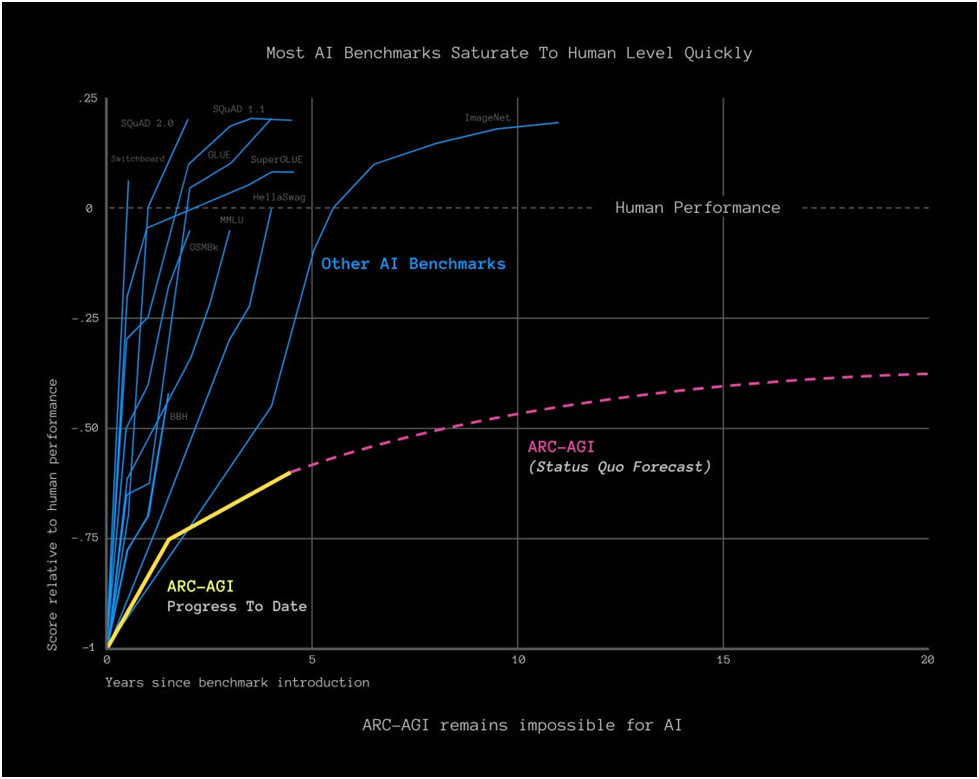
Notice how the widely ballyhooed benchmarks all surpass human intelligence (no wonder readers are confused). But the lowly ARC test peters out far below human level performance (the best so far is 34% of the answers correct, which of course isn’t even as good as flipping a coin). What makes Chollet’s test different? It tests basic commonsense knowledge that we all have (from the article):
- Objectness
Objects persist and cannot appear or disappear without reason. Objects can interact or not depending on the circumstances. - Goal-directedness
Objects can be animate or inanimate. Some objects are “agents” — they have intentions and they pursue goals. - Numbers & counting
Objects can be counted or sorted by their shape, appearance, or movement using basic mathematics like addition, subtraction, and comparison. - Basic geometry & topology
Objects can be shapes like rectangles, triangles, and circles which can be mirrored, rotated, translated, deformed, combined, repeated, etc. Differences in distances can be detected.
So, there’s the rub. How does the pretty lady escaped drowning with hands and feet shackled underwater in a glass cage, to the oohs and aahs of the crowd? Folks like Gary Marcus, François Chollet, Melanie Mitchell, me and other critics have been watching the fireworks knowing that something’s amiss and the emperor has no clothes. But Chollet has really put his finger on the core problems.
Data crunching—even massive data crunching using deep neural networks and transformers—is still a brain in the vat. No, more than that, it’s still a fake form of AI, and talk of a coming AGI following the same path is wasting time, resources, and money—and proving yet again that the hype cycle of AI seems never to end. I think Jeff Hawkins, Palm Pilot inventor-turned- neuroscientist put it best when he pointed out in A Thousand Brains: A New Theory of Intelligence (2021) that today’s AI doesn’t know anything: “Deep learning networks work well, but not because they solved the knowledge representation problem. They work well because they avoided it.”
That’s sort of like getting a date by using someone else’s photos.
Other Smart Critics Worth Following
Melanie Mitchell is well worth reading to get to the truth about AI. As she puts it, referring to LLMs tested against human performance: AI surpassing humans on a benchmark that is named after a general ability is not the same as AI surpassing humans on that general ability.
Emily Bender, a computational linguist at the University of Washington in Seattle, has also been properly (scientifically) critical, notoriously referring to OpenAI’s GPT technology in an early and prescient paper as a “stochastic parrot,” providing impressive responses but possessing no real understanding.
Reality Check
Virtual reality pioneer, entrepreneur and culture critic Jaron Lanier once quipped “It’s the critics who are the real optimists. It’s the critics who drive improvement.” That’s how I see Chollet’s ARC framework. It’s a reckoning for the hypesters, sure, but it’s also a call for change, for new directions in AI research and new imaginative and innovative ideas. As things stand, the field is all too willing to claim victory while the party’s on, and change the subject during the hangover. Humans are good at discovering; let’s discover something better.
At any rate, a reality check for LLMs is inevitable, and with OpenAI, “Project Strawberry,” and the new hype cycle, thanks to Chollet and others, it’s already here.