
One Way Human Vision Is Better Than a Machine’s
The problem machine vision has with understanding what things *should* look like creates risks for traffic video safety systems, researchers sayBecause machine vision absorbs information without context, it simply doesn’t “see” what a human sees — and the results could be “dangerous in real-world AI applications,” warns York University prof James Elder.
He and his colleagues did an interesting experiment with deep convolutional neural networks (DCNNs). They used “Frankensteins” — models of life forms that are distorted in some way — to determine how they would be interpreted by humans or by machine vision:
“Frankensteins are simply objects that have been taken apart and put back together the wrong way around,” says Elder. “As a result, they have all the right local features, but in the wrong places.”
The investigators found that while the human visual system is confused by Frankensteins, DCNNs are not — revealing an insensitivity to configural object properties.
York University, “Even smartest AI models don’t match human visual processing” at ScienceDaily (September 16, 2022) The paper is open access.
Why doesn’t lack of confusion in such cases make the machine vision better than human vision? Let’s look at a test diagram that the researchers used:
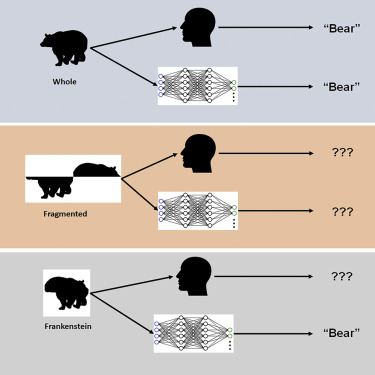
The machine figured out that the object in the diagram is a bear even though the top half and the bottom half are misaligned. The human is still confused because no bear actually looks (or could look) that way.
One such application is traffic video safety systems: “The objects in a busy traffic scene – the vehicles, bicycles and pedestrians – obstruct each other and arrive at the eye of a driver as a jumble of disconnected fragments,” explains Elder. “The brain needs to correctly group those fragments to identify the correct categories and locations of the objects. An AI system for traffic safety monitoring that is only able to perceive the fragments individually will fail at this task, potentially misunderstanding risks to vulnerable road users.”
“Study: Even smartest AI models don’t match human visual processing” at News@York (September 16, 2022)
Will machine vision note the significance of a woman, her bike, and the tow buggy with a toddler inside all lying parallel on the road? Maybe. Its camera might also pick up a dozen human passersby immediately rushing onto the scene as all traffic stops and a number of car doors open…
Configurations are significant and machine vision developers may have work to do there:
According to the researchers, modifications to training and architecture aimed at making networks more brain-like did not lead to configural processing, and none of the networks were able to accurately predict trial-by-trial human object judgements. “We speculate that to match human configural sensitivity, networks must be trained to solve a broader range of object tasks beyond category recognition,” notes Elder.
“Study: Even smartest AI models don’t match human visual processing” at News@York (September 16, 2022)
You may also wish to read: Researchers: Deep Learning vision is very different from human vision. Mistaking a teapot shape for a golf ball, due to surface features, is one striking example from a recent open-access paper. The networks did “a poor job of identifying such items as a butterfly, an airplane and a banana,” according to the researchers. The explanation they propose is that “Humans see the entire object, while the artificial intelligence networks identify fragments of the object.” Also: Mis-seeing can include mistaking a schoolbus for a snowplow.