
Retracted Paper Is a Compelling Case for Reform
The credibility of science is being undermined by misuse of the tools created by scientists. Here's an example from an economics paper I was asked to comment on
The central theme of my book, Distrust (Oxford 2023), is that the credibility of science is being undermined by tools created by scientists. The internet spreads disinformation far and fast; tests of statistical significance encourage researchers to torture data; and large databases and powerful computers encourage researchers to data mine. Torturing data is also known as p-hacking and data mining is also known as HARKing (Hypothesizing After the Results are Known). Together they have fueled the ongoing replication crisis in which attempts to replicate peer-reviewed research articles with fresh data fail.
It’s even worse when researchers make up data, often in support of a particular agenda but sometimes just to fast-track their careers. For example, Diederik Stapel wrote (or co-authored) hundreds of papers, many on media-friendly topics, such as claims that eating meat makes people selfish and that people eat more M&Ms from a coffee mug with the word “capitalism” printed on it.
After obtaining his PhD in Social Psychology in 1997, Stapel received a Career Trajectory Award from the Society of Experimental Social Psychology in 2009 and became dean of the Tilburg School of Social and Behavioral Sciences in 2010. In 2011, he confessed that he had either manipulated or completely fabricated much of his data because, “I wanted too much too fast.” Tilburg fired him in 2011 and 58 of his papers have now been retracted by the journals that published them. His Career Trajectory award was also retracted and he relinquished his PhD. Instead of hiding in shame, in 2012 he wrote a book Ontsporing (“Derailment”) about his misdeeds!
Learning to spot data manipulation earlier
Retraction Watch is a website that Ivan Oransky and Adam Marcus created in 2010 to maintain a database of published research papers that have been retracted because of scientific misconduct.
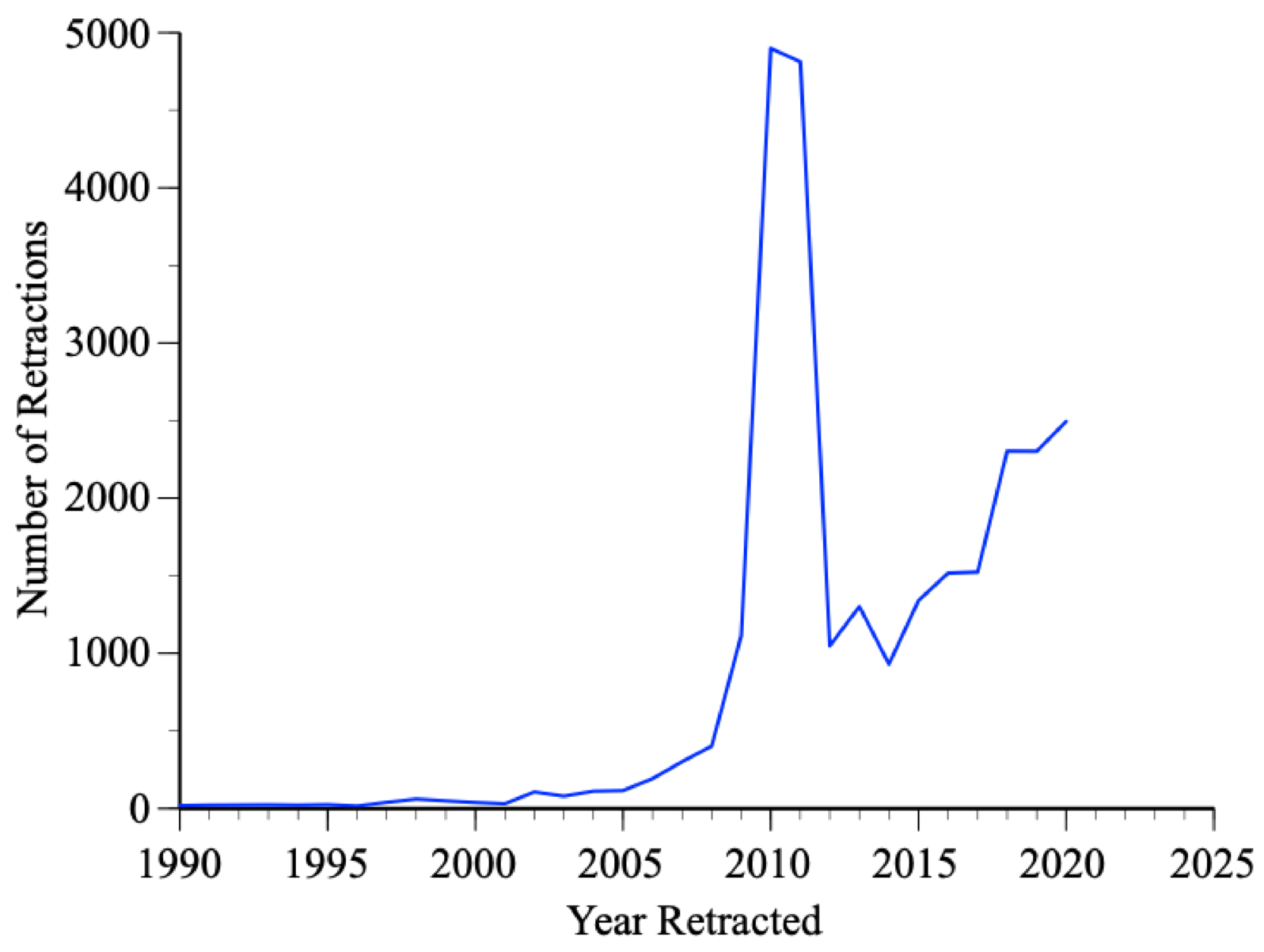
The figure below of the number of retractions recorded in their database since 1990 shows a spike in 2010 and 2011. That was mostly due to the Institute of Electrical and Electronics (IEEE) retracting thousands of conference papers for undisclosed reasons. There are now more than 50,000 retractions in their database and the number that should be retracted is surely much larger than this—since there is little incentive for outsiders to scrutinize other people’s publications carefully.
I recently saw first-hand how hard it can be to check a published paper carefully. Frederik Joelving, a journalist with Retraction Watch, contacted me on January 30 about a paper written by two prominent economists, Almas Heshmati and Mike Tsionas, using 1990–2018 data for 19 variables for 27 countries, a total of 14,877 observations. The paper said that their data were a “balanced panel,” which is a technical label for data with no missing observations.
A PhD student who was coincidentally working with much of the same data knew that there were, in fact, lots of missing observations. He contacted Heshmati (Tsionas is recently deceased) and eventually persuaded Heshmati to share the data used in the paper after the student promised not to show the spreadsheet to anyone else.
When he realized how misleading the paper was, the student did share the data with Joelving, who then shared the data with me. We spent many hours studying these data. We no doubt missed some problems but what we found was deeply troubling.
What does a deeply troubling dataset look like?
The dataset was, in fact, missing nearly 2,000 observations (13% of the total), and Heshmati had plugged most of these holes by using Excel’s autofill function to impute missing values. The missing data were often clustered, which increased the fragility of imputed data.
For example, one of the variables (MKTcap) is the market value of a nation’s corporations, as a percentage of the nation’s GDP. Finland, Denmark, and Sweden, were missing the last 13, 14, and 15 consecutive years of data, respectively. The authors filled in these missing numbers by extrapolation, even though it is surely dodgy to project so many years into the future, particularly for something as volatile as stock prices. Greece was missing its first 11 years of MKTcap data, and Italy was missing its first 9 years and last 10 years. No problem! Just extrapolate forward and backwards.
Even worse, there were five cases where there were no observations at all for a country. The authors handled this by copying and pasting data from other countries. Iceland, for instance, has no MKTcap data, so all 29 years of Japanese data were pasted into the Iceland cells. Other than both being islands formed by volcanic activity, it is hard to think of anything they have in common. It is certainly outrageous to think their MKTcap data would be identical. And the authors did this wholesale copying and pasting five times!
Joelving wrote a Retraction Watch piece about this on February 5. I wrote a piece on February 21. On February 22, the journal that published this flawed paper retracted it.
Facing retraction, what did the first author say?
There are several takeaways. In an email to Retraction Watch, Heshmati argued that, “If we do not use imputation, such data is almost useless.” First, the solution to an absence of data is not to fabricate data. Second, his argument reveals the pressure researchers feel to product statistically significant results.
Heshmati also told Retraction Watch that, “If I had to start over again, I would have managed the data in the same way as the alternative would mean dropping several countries and years.” Clearly, he did not think he had done anything wrong. The journal that retracted the paper felt otherwise.
Reforms needed
One of my reform suggestions in Distrust is that, “Statistics courses in all disciplines should include substantial discussion of p-hacking and HARKing.” Heshmati should have known better. All researchers should know better. Another reform that I recommended in Distrust is that, “Journals should not publish empirical research until nonconfidential data and a detailed description of the methods are made publicly available.” This case is a compelling example of the need for this reform. Too often, authors refuse to share their data after publication. Heshmati did so reluctantly and only after the student promised not to show the data to anyone else.
The student has been both criticized for breaking his promise and celebrated for being a whistleblower. None of this should be necessary. In addition, if authors are compelled to make their data available publicly, they may be more reluctant to engage in unseemly shenanigans.
You may also wish to read: Why chatbots (LLMs) flunk Grade 9 math tests. Lack of true understanding is the Achilles heel of Large Language Models (LLMs). Have a look at the excruciating results. Chatbots don’t understand, in any meaningful sense, what words mean and therefore do not know how the given numbers should be used. (Gary Smith)