
How Does A Kubernetes Cluster Work?
A general overview of the Kubernetes environmentNow that you have some concrete experience using Kubernetes, this article will present the basic theory of how a Kubernetes cluster works. We won’t talk about how to accomplish these things in the present article – the goal is to provide you with a broad understanding of the components of Kubernetes.
Basic Kubernetes Components
Kubernetes comes with a lot of different components, and it is hard to get them all shown on the same diagram. Therefore, I will just give a high-level picture of what a Kubernetes cluster looks like. The image below shows the basic setup, which we will cover in this article.
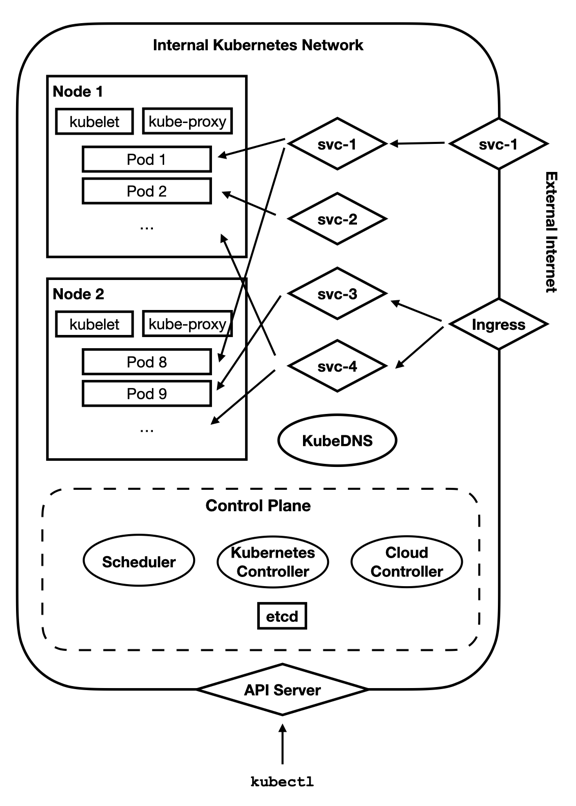
You see here a separation between the internal Kubernetes network and the Internet. Note that this separation is not necessarily physically enforced. That is, depending on your cluster provider, this traffic may or may not be cordoned off from the rest of the Internet. When running your cluster on Linode, Kubernetes traffic is only seen by nodes within the cluster, but that is not a general Kubernetes guarantee.
The Control Plane
Within the Kubernetes cluster, there is a control plane. This is the cluster management center. All of the decision-making about the cluster occurs here. What is the present state of the cluster? Do we need to launch more Pods for a Deployment? Those sorts of decisions are made by the control plane.
You can think of the control plane as being divided up into several pieces:
- The cloud controller is used for interacting with native resources from your cloud provider. While Kubernetes provides a lot of functionality, some features (such as load balancers, physical hardware, and disk drives) are rooted in the cloud’s platform itself.
- The Kubernetes controller is used for interacting with Kubernetes-provided resources. The Kubernetes controller performs the physical actions associated with launching Pods, Services, and other features that run on top of the cloud-provided resources. There are usually separate controllers for various different aspects of Kubernetes.
- The scheduler figures out what needs to be done. The scheduler figures out when Pods need to be deployed, and what Nodes they need to be deployed on.
etcdstores the configuration and state of the entire cluster. All of the other services useetcdto know what they should be doing.
The control plane is accessed through the API server, which acts as the gateway into the Kubernetes cluster. Essentially, whenever you use kubectl (the Kubernetes control command), it talks to the API server, which then tells the control plane what to do. You will rarely if ever need to directly worry about what happens on the control plane itself. Just realize that Kubernetes is running several processes to keep your cluster working the way that you have requested it.
Nodes and Pods
Within the cluster are Nodes. A Node is essentially a physical or virtual machine allocated to the cluster. Each Node runs two required processes – kubelet, which physically launches Pods as requested from the control plane, and kube-proxy, which keeps the networking rules on the Node up to date with those specified in the cluster, and makes sure that the Pods can access all of the cluster resources they are permitted to.
The kubelet process launches Pods, which are the basic unit of management in Kubernetes. A Pod usually consists of a single running container, but they can actually be configured to be running more than one container for more advanced use cases.
Workloads
A workload is the management tool for launching Pods. While a Pod can be managed and launched individually, usually they are launched as part of a workload, which provides additional visibility for making sure that the Pod is up and running when it is supposed to be.
There are a few basic workload types in Kubernetes:
Deployment / Replica Set
A Replica Set manages a number of Pods which should all be running the same containers and configuration. As we saw in the previous article, Replica Sets are usually themselves managed by Deployments, which handle deploying and migrating gracefully between versions of the Replica Set.
Stateful Set
A Stateful Set is like a Replica Set, but the member Pods are not necessarily identical, and may require some amount of ordering to properly boot up. These usually also have some sort of permanent storage attached to them.
Daemon Set
A Daemon Set is used to schedule Pods that run per Node in your cluster (for instance, an intrusion detection monitor).
Job / Cron Job
A Job defines a process that runs to a completion point and then stops. A Cron Job is a Job that recurs according to a set schedule.
Kubernetes Services
A Service is used to identify a feature of the cluster. Services provide stable endpoints to hit, even when the underlying Pods may be continually recycling. A Service, when it is first deployed, receives a stable IP address on the cluster that the cluster uses to access that Service as long as it is deployed. Whether the Service is served by one or many underlying Pods, the rest of the cluster does not worry about the specifics of the Pods, it just directs traffic to the Service.
There are several types of Services as well:
ClusterIP
A ClusterIP service is simply an IP address internal to the cluster which routes traffic to one or more underlying Pods. You can think of it as a load balancer that is internal to the network.
LoadBalancer
A LoadBalancer service is like a ClusterIP, but the IP address is exposed outside of the network, usually using a load balancing technology that is native to the cloud platform you are using. Since this relies on the native cloud implementation, if you have set up Kubernetes on your own personal hardware, you may not have access to this service type. However, it is available on most cloud providers.
NodePort
A NodePort sets up an externally-facing port on every Node which proxies that port to the Pods that implement the service. This is useful if you have set up your own Kubernetes cluster yourself and don’t have access to load balancers.
ExternalName
An ExternalName service simply gives an internal name to an external DNS name. For instance, one could imagine setting up a service named to refer to customsearch.googleapis.com. These do not generally refer traffic to Pods within the cluster.
In the image we showed earlier, several Services are shown. The Service svc-2 is a ClusterIP Service – it is an internal-only service that is available only to Pods on the cluster. The Service svc-1 is a LoadBalancer Service – it is exposed externally to the public. However, it also operates internally to the cluster like a ClusterIP Service.
The Services svc-3 and svc-4 are ClusterIP services, but are made available to the external world through an Ingress. An Ingress is similar to a Service, but is layered on top of existing Services. An Ingress is primarily used for allowing access to cluster Services from the outside.
Ingresses are different from LoadBalancer services because they offer several features unique to HTTP services. First of all, an Ingress handles SSL termination. What this means is that certificate handling only has to be set up on the Ingress, and traffic can flow and be handled unencrypted throughout the rest of the cluster. This makes managing and updating certificates much easier than trying to make sure each Pod has the right setup. Additionally, since this is handled on the Ingress (and not in the Pod itself), certificate management becomes an infrastructure issue, not an application issue. This allows your developers to worry about the application, and your devops/sysadmins/netadmins to worry about the certificates. However, this presumes that traffic flowing inside your Kubernetes network is either isolated or encrypted, which depends on your provider.
Another purpose for an Ingress is to manage URL paths that are developed and maintained as separate applications. Many APIs are structured so that certain hostnames and paths are really separate Services. Ingresses provide a way to say, for instance, that /my-app gets forwarded to one Service, and /my-other-app gets forwarded to another. This allows the individual Services to be managed and updated separately (perhaps by separate teams) but merged into a unified API when accessed by the external world.
KubeDNS
So, if we deploy a Service in Kubernetes, how do the Pods find the Service? In Kubernetes, a Service is given a fixed name and a fixed internal cluster IP address. Then, it stores the name-to-address mapping in KubeDNS, which is the local DNS provider for all Pods on your Kubernetes cluster.
KubeDNS allows you to simply give your service a name, and know that the name will be respected in all Pods within the cluster. Because the cluster creates a unique internal IP address for the Service, it is fine if your Pod caches the resolved address of the Service – that IP address will be fixed as long as the Service exists on the cluster.
There is very little about Kubernetes itself that your Pods or their containers need to know. Rarely do Pods interact with the Kubernetes API Server, or even the kubelet running on its own Node. For the most part, the structure of the Kubernetes cluster is relayed to Pods as hostnames. Simply because KubeDNS is the default resolver for the cluster, all name-based Service lookups will automatically find the right IP address.
Conclusion
As you can see, Kubernetes has a lot of components available for putting together a cluster. Workloads provide the means of launching Pods to do processing work, Services and Ingresses provide the means of accessing a group of Pods as a unified service, and KubeDNS provides the glue to put them all together.
In case you missed it…
Getting Started with Kubernetes: A Brief History of Cloud Hosting. A history lesson for a better understanding of why web infrastructure hosting is the way it is. Way back in the early days of the Internet, web applications were hosted on specific server machines. Much has changed since then. (Jonathan Bartlett)
Getting Started with Kubernetes: A Cluster Setup Walkthrough. Setting up a Kubernetes cluster in Linode is incredibly simple. Amazon gives and Amazon takes away. Therefore, it is wise to not tie your infrastructure too tightly to a single vendor. (Jonathan Bartlett)