
AI: Still Just Curve Fitting, Not Finding a Theory of Everything
The AI Feynman algorithm is impressive, as the New York Times notes, but it doesn’t devise any laws of physicsJudea Pearl, a winner of the Turing Award (the “Nobel Prize of computing”), has argued that, “All the impressive achievements of deep learning amount to just curve fitting.” Finding patterns in data may be useful but it is not real intelligence.
A recent New York Times article, “Can a Computer Devise a Theory of Everything?” suggested that Pearl is wrong because computer algorithms have moved beyond mere curve fitting. Stephen Hawking’s 1980 prediction that, “The end might not be in sight for theoretical physics, but it might be in sight for theoretical physicists” was quoted. If computers can now devise theories that make theoretical physicists redundant, then they are surely smarter than the rest of us.
The program behind the Times headline is a neural-network algorithm dubbed AI Feynman, created by MIT professor Max Tegmark and a student Silviu-Marian Udrescu. It had successfully rediscovered 100 physics equations from the celebrated textbook, The Feynman Lectures on Physics.
Professor Tegmark argued that, “We’re hoping to discover all kinds of new laws of physics. We’re already shown that it can rediscover laws of physics.” If computer algorithms can indeed discover laws of physics, that would be far beyond mere curve fitting. Alas, such prowess remains a long way off, as does Hawking’s prediction of the demise of theoretical physicists.
Pearl is still correct.
The AI Feynman algorithm is impressive but it doesn’t devise any laws of physics. The researchers used each of Feynman’s equations to generate data. The algorithm was then told the variables in the equation and tasked with identifying the form of the mathematical relationship that generated the data. It is curve fitting on steroids, but it is still just curve fitting.
Consider the equation for Newton’s Law of Universal Gravitation,
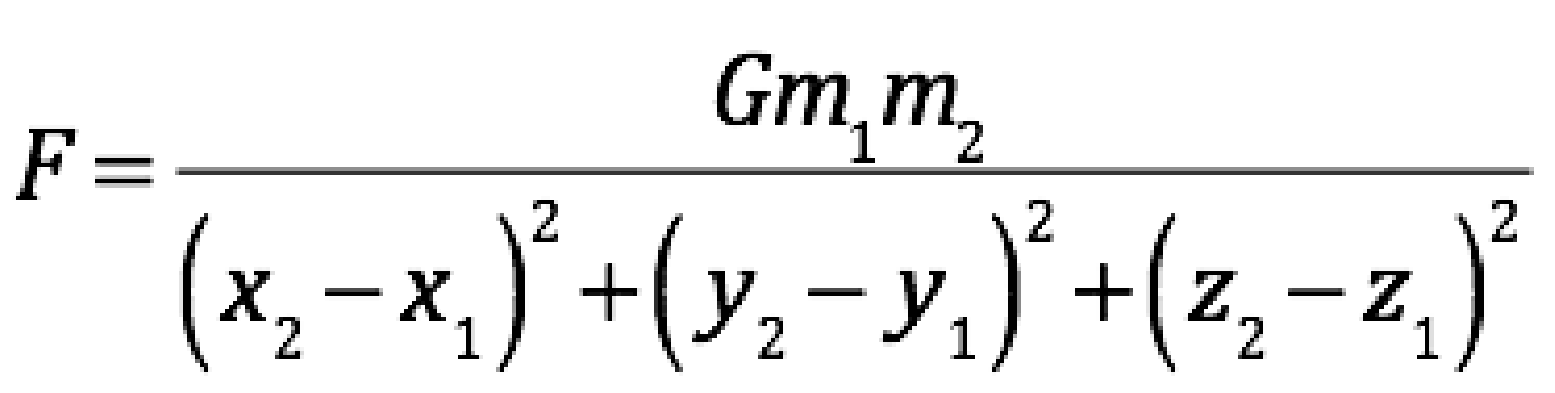
where F is the force between the two objects, G is the gravitational constant, m1 and m2 are the masses of the two objects, and the denominator is the squared distance between the centers of the objects. The theoretical insight that led to this equation was Newton’s conjecture that gravitational attraction is positively related to the objects’ masses and inversely related to the distance between them. Newton used the real-world data available to him to specify a functional form that fit the data and was consistent with these insights.
In the AI Feynman test, the researchers used the value of the gravitational constant and a variety of assumed values for the other eight variables on the right hand side of Newton’s equation to calculate the implied values of F. The algorithm’s task was to reverse engineer the process by identifying the functional form that gives these values of F for the specified values of the explanatory variables. It took the AI Feynman algorithm only 5,975 seconds using 1,000,000 observations to identify the correct equation.
Unlike Newton, AI Feynman did not have to decide which variables determine gravitational force. That would have required real intelligence—specifically, a knowledge of what force, mass, and distance are and how they might be related. Instead, the algorithm was told the variables that are in Newton’s equation and its task was to curve fit.
In addition, the algorithm did not know when it had found the right equation; it needed the humans monitoring the algorithm to say, “Yes, that’s it.”
The researchers reported that one million data points were needed for AI Feynman’s best-fit equation to match Newton’s equation. Therefore, the algorithm’s best-fit equations with fewer observations must have been wrong. Suppose that one of the best-fit equations with fewer than a million data points happened to look like this:
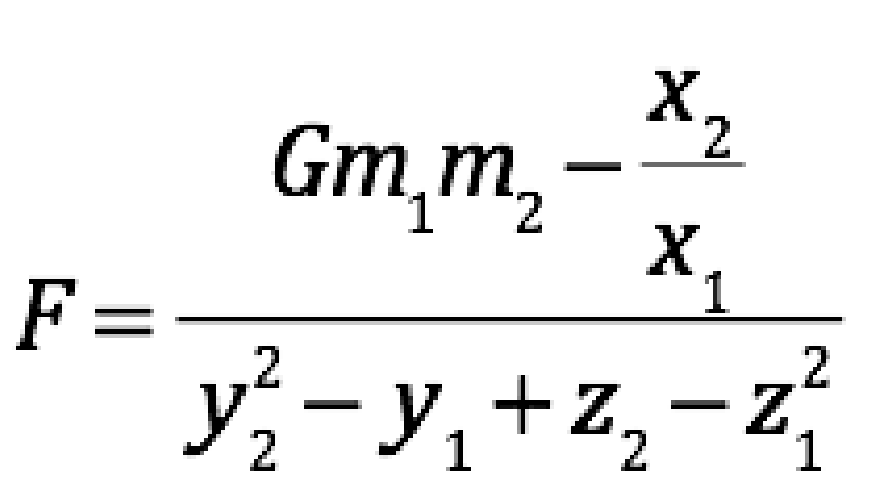
A human expert would immediately recognize this equation as nonsense. There is no logical difference between the x, y, and z coordinates so they should enter the equation in exactly the same way. Further, the only logical way that the coordinates could matter is if they are arranged exactly as given in Newton’s law so that they measure the distance between the two objects.
When AI Feynman selected an incorrect equation such as this, the researchers recognized that it was wrong because they knew the desired answer ahead of time and they kept adding more data until the algorithm found the “right” answer. An algorithm never knows when an equation is correct and when it is nonsense because it doesn’t know what any of the variables mean, let alone how and why they might be related. Even worse, if an algorithm were starting from scratch, using real world data to attempt to discover a new theory, there is no pre-specified “right” answer to match.
AI Feynman is a remarkable algorithm. The researchers note that, for many of the equations they considered, brute force curve-fitting would take longer than the age of our universe, while AI Feynman’s curve fitting generally took less than a minute, using only 10 data points. However, there are good reasons for skepticism about the ability of AI algorithms to devise theories:
1.The researchers noted that, “Generic functions are extremely complicated and near impossible for symbolic regression to discover. However, functions appearing in physics and many other scientific applications often have simplifying properties that make them easier to discover;” for example, they usually consist partly or completely of low-order polynomials. Some models in other fields are far more complicated.
2.None of Feynman’s 100 equations has more than nine explanatory variables. Models in some fields have dozens of explanatory variables, which can make the required computational time impractical even for AI Feynman.
3.The AI Feynman tests assumed that all of the explanatory variables are measured perfectly and that the value of the dependent variable is either exactly what the equation says it should be or has a relatively small amount of noise. In the real world, we don’t have the luxury of generating data from known equations; instead, our task is to specify a model that explains messy data. Variables are often measured with substantial noise and the dependent variable may be buffeted by the effects of unobserved variables. For example, stock prices are affected by imperfectly measured investor expectations about the economy and also by unmeasurable emotions (what Keynes called “animal spirits”). Models of stock prices based on curve fitting are notoriously useless.
4.An essential part of modeling is the specification of the explanatory variables. Current AI algorithms do not have the theory, logic, wisdom, or common sense to make such choices and variable selection based on curve fitting is treacherous.
5.Curve-fitting algorithms are prone to overfitting the inclusion of extraneous explanatory variables that happen to be coincidentally correlated with the dependent variable. Models that are overfit do poorly with fresh data because the inclusion of extraneous variables not only adds noise but can also crowd out true explanatory variables.
6.A more subtle problem with overfitting is the potential for implausible functional forms. For example, the theory that household spending is related to income is compelling. Households with more income generally spend more, though the relationship is not perfect because other factors matter too. Factors might include the number of people in the household, the ages of household members, and household wealth. The figure below shows a simple scatter plot using hypothetical data on household income and spending. It seems perfectly reasonable to fit a straight line to these data and to interpret the variation in the points about the line as fluctuations due to factors that are not in the model.
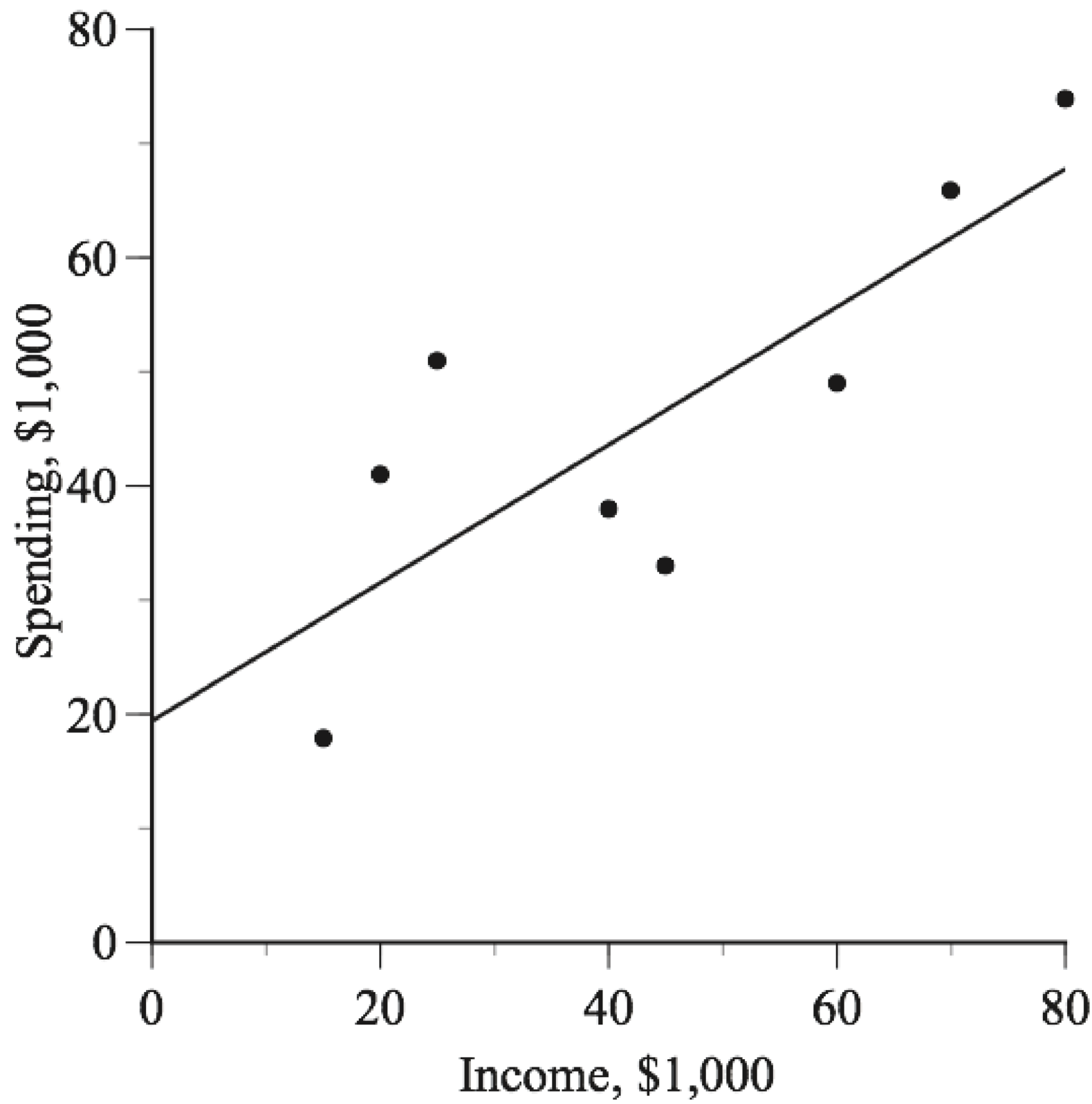
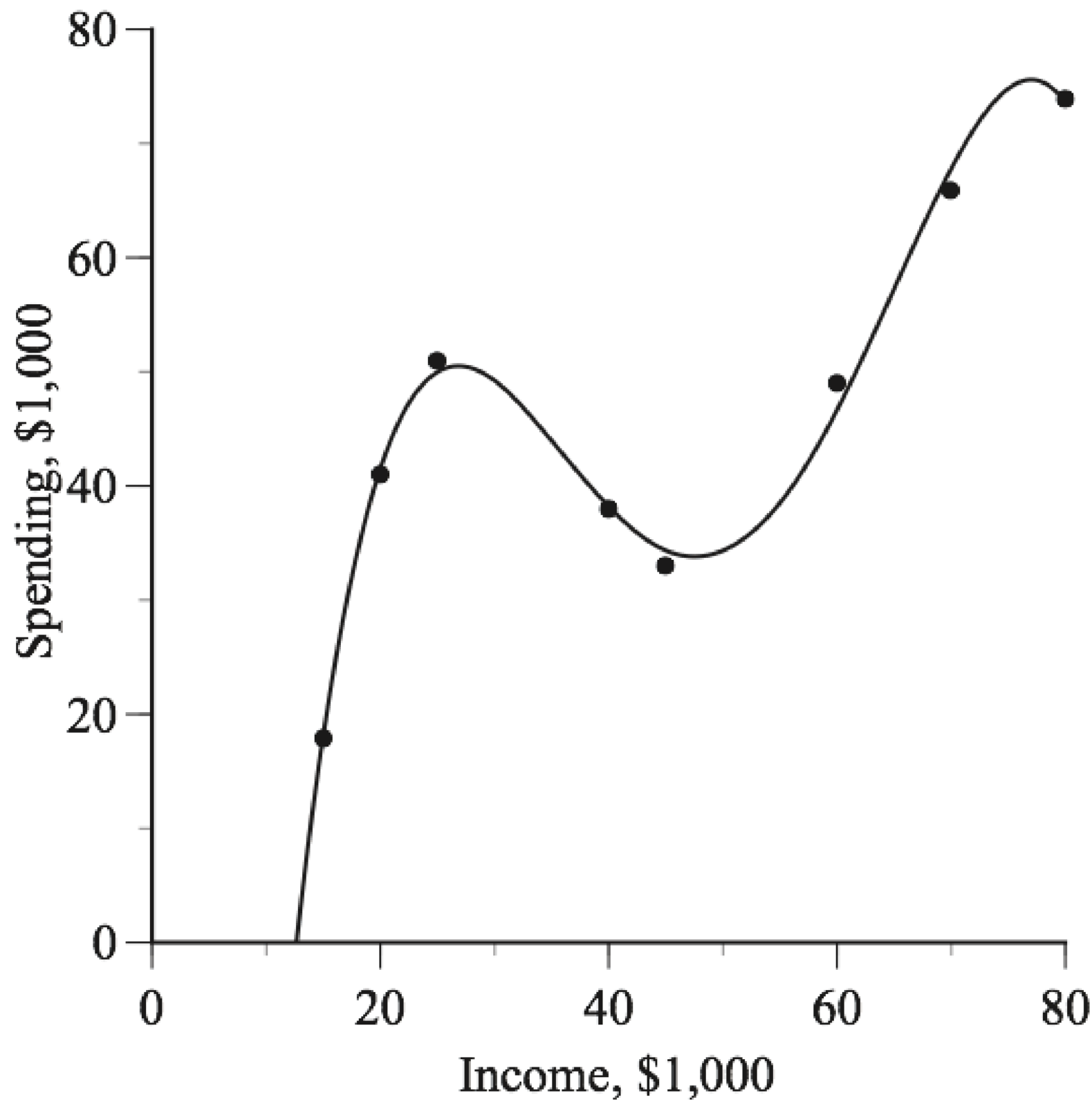
The next figure shows what happens when an algorithm overfits the data by using a nonlinear model to fit the data almost perfectly. Despite the near-perfect fit, the model’s predictions are sometimes bizarre; for example, households with $25,000 income are predicted to spend more than do households with $50,000 income.
When the data can be plotted in a simple scatter diagram, it is obvious that, despite the great fit, the nonlinear model is worse than a simple linear model. Problems arise, however, when a model has many variables, and we can’t use a simple scatter diagram to reveal the model’s flaws. What is certain is that mindless curve fitting is unreliable.
AI algorithms can be astonishingly good at highly focused tasks that benefit from fast, accurate calculations. However, they are far less successful at tasks that benefit from logical reasoning and creativity. Computers are much better than humans at curve fitting but they are still far worse at devising models that can be used to help understand the world and make reliably accurate predictions.
You may also enjoy these articles on AI by Gary Smith:
Cancer maps—an expensive source of phantom patterns?
Is the money the U.S. government spends on tracking cancer patterns a good investment? There’s a way we can tell.
and
The decline effect: Why most medical treatments are disappointing. Artificial intelligence is not an answer to this problem, as Walmart may soon discover.