
The Internet’s Structure Builds In Privacy Flaws
The Domain Name resolver knows every service you visit, and every service those services rely on, as you move around the internetWe hear a lot about how social media services use AI and machine learning to surveil us and build individual profiles of each of us. We don’t hear nearly so much about the way email and search can be used to build a more complete profile. In addition to all that, one system is so big a presence that it is almost invisible to the average user—and yet it is crucial to the way the Internet operates.
I am talking about the Domain Name Service, or DNS, which translates service names into addresses (topological locations) on the Internet. It might not be obvious at first, but the Internet is very much like a large road network. Servers, which can be compared to storefront businesses, and hosts (computers, smartphones, tablets, televisions, and other devices), which can be compared to houses, are both connected to this network of networks. Just like the homes, businesses, etc., that can be reached via the road network, each of these devices has an address.
While the road network uses street names and numbers to describe a physical location, the internet uses Internet Protocol, or IP, addresses. There is one slight difference between an IP address and a street address—IP addresses designate a topological location while street addresses denote a physical location.
To understand how DNS works, imagine using an old-fashioned phone book or online search engine to find the address of a local pizza parlor. You look up the name of the business, and the phone book or search engine returns a physical address. If you know your way around the area, you can use this address to find the pizza parlor directly; if not, you can ask for directions, or consult a map or mapping software.
DNS serves the same purpose on the internet. If you type mindmatters.ai into your browser’s address bar, the computer looks up this name using DNS to find an IP address. By sending information (packets) to this IP address, your local host (computer, smartphone, etc.) can connect to the server where the service mindmatters.ai is running. The process is illustrated below:
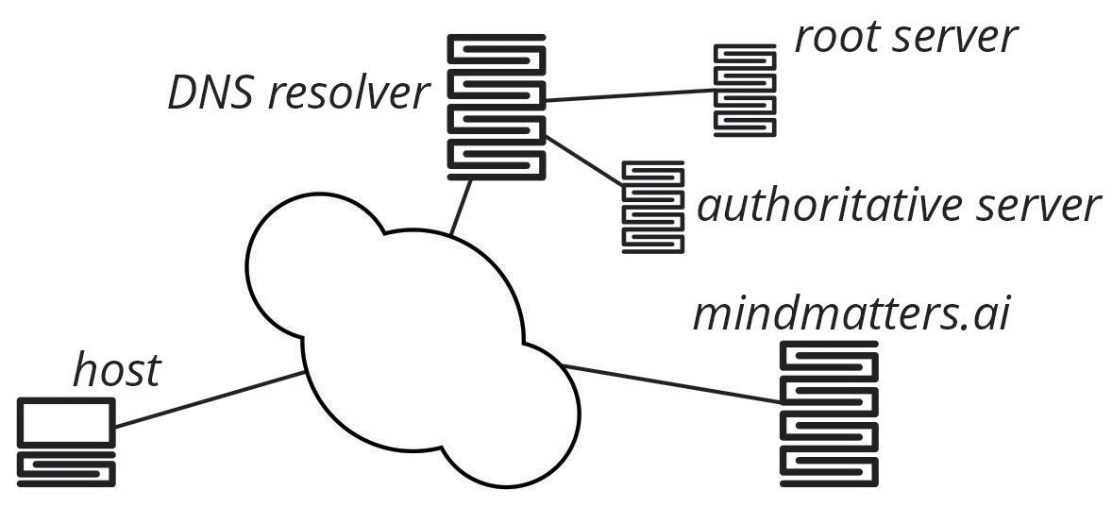
In this figure, the host needs to know where mindmatters.ai is connected to the Internet, so it queries the DNS resolver. The DNS resolver, in turn, recursively queries the root, top level domain, and authoritative servers to discover the IP address associated with mindmatters.ai. Once the DNS resolver has determined this information, it returns the correct IP address to the host, which can then connect to the server on which mindmatters.ai is located.
This is a basic outline; the actual process is more complex. But this outline shows the critical role that the resolve (the resolution of an address) plays in navigating the Internet. The resolver, in short, knows every service you visit, and every service those services rely on as you move around the internet—because your computer is always asking for directions. Whoever owns the resolver can discover a lot of information about you or the organization for which you work. Picture it as a telephone book that keeps notes on who you tried to call, notes that may be available to someone else.
For instance, let’s say you look up the web site of a local doctor. Probably, you are either searching for a new doctor or setting up an appointment to see the doctor. By combining this information with your recent searches, for example, for “risk factors for diabetes,” an interested viewer of your search history might glean that your interest in diabetes is not mere curiosity; you may be making an appointment to find out if you have that disease. Who do you think should have that information?
This is clearly a pretty serious privacy risk and the Internet Engineering Task Force (the IETF) has been struggling with it for years:
The IETF’s position of refusal to standardize surveillance-enabling architecture modifications twenty years ago did not settle the matter then and hasn’t settled it now. Code and standard specifications of network protocols do not necessarily usurp our laws, and code, law, and markets are all elements in a political tussle over what ultimately determines social policies and practices.
Geoff Huston, “DNS Privacy and the IETF” at The Internet Protocol Journal
The IETF seeks to make the DNS system more private but the problem is not motivational; it is structural. How can you create a directory that anyone can access and yet keep what everyone is asking for private? Short of moving to a paper-based DNS system (think, a stack of New York City-size telephone directories), there isn’t a good answer within the present system.
We can at least try to prevent the DNS system from morphing into the harvest field of sensitive personal information that search engines and social media networks have become. For example, at a personal level, you can seek out and switch to more private options (virtual private networks), or DNS servers run by nonprofits, such as those run by Quad9, Verisign, or perhaps CloudFlare.
Also by Russ White: You think you have nothing to hide? Then why are Big Tech moguls making billions from what you and others tell them?
and
Why you can’t just ask social media to forget you. While we now have a clear picture of the challenges current social media pose to peoples and cultures, what to do is unclear
Further reading on data privacy:
Many parents ignore the risks of posting kids’ data online. The lifelong digital footprint, which starts before birth, makes identity theft much easier.
and
Ad exec quit the industry over Big Tech’s relentless snooping. He was shocked by the brazen attitude to the invasion of privacy
Featured image: Internet privacy/peterschreibermedia, Adobe Stock