
Artificial Unintelligence
The failure of computer programs to recognize a rudimentary drawing of a wagon reveals the vast differences between artificial and human intelligenceIn 1979, when he was just 34 years old, Douglas Hofstadter won a National Book Award and Pulitzer Prize for his book, Gödel, Escher, Bach: An Eternal Golden Braid, which explored how our brains work and how computers might someday mimic human thought. He has spent his life trying to solve this incredibly difficult puzzle. How do humans learn from experience? How do we understand the world we live in? Where do emotions come from? How do we make decisions? Can we write inflexible computer code that will mimic the mysteriously flexible human mind?

Hofstadter has concluded that analogy is “the fuel and fire of thinking.” When humans see, hear, or read something, we can focus on the most salient features, its “skeletal essence.” Humans understand this essence by drawing analogies to other experiences and they use this essence to add to their collection of experiences. Hofstadter argues that human intelligence is fundamentally about collecting and categorizing human experiences, which can then be compared, contrasted, and combined.
To Hofstadter’s dismay, computer science has gone off in another direction. Computer software became useful (and profitable) when computer scientists stopped trying to imitate the human brain and, instead, focused on the ability of computers to store, retrieve, and process information.
Limiting the scope of computer science research has limited its potential. Hofstadter lamented that, “To me, as a fledgling [artificial intelligence] person, it was self-evident that I did not want to get involved in that trickery. It was obvious: I don’t want to be involved in passing off some fancy program’s behavior for intelligence when I know that it has nothing to do with intelligence.”
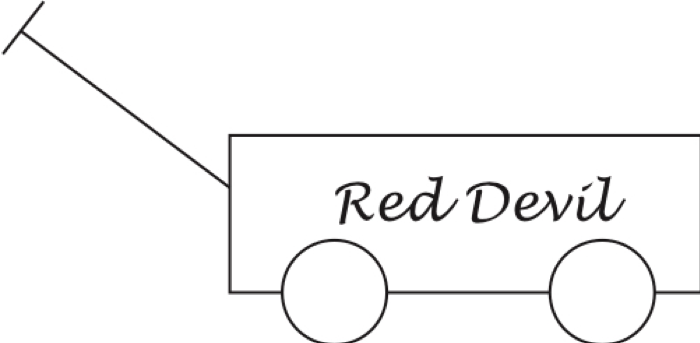
Humans see things for what they are. When we see the drawing below, we instantly grasp its skeletal essence (the box, wheels, and handle) and understand how these are related. This is clearly a wagon.
When we were young, we might have seen a cardboard box with four sides and a bottom and been told that this is a box, so we created a single-member category. Then we learn that a box with a top is still a box. So is a box made out of wood or plastic. Some boxes are large; some are small. Some are empty; some are full. Some are red; some are white. Our mental box category is fluid and flexible.
Then we learn that a box with wheels and a handle is called a wagon, and we create a new mental category that encompasses the wagons we encounter of different sizes and colors, made of different materials, and used for different purposes.
Computers do nothing of the sort. They are shown millions of pictures of boxes, wagons, horses, stop signs, and more, and create mathematical representations of the pixels. Then, when shown a new image, they create a mathematical representation of these pixels and look for matches in their database. The process is brittle—sometimes yielding impressive matches, other times giving hilarious mismatches.
A few years ago, I asked a prominent computer scientist to use a state-of-the-art deep neural network computer program to identify the image above, the program was 98 percent certain that the image was a business—perhaps because the text on the rectangle resembled a storefront sign in its database. More recently, the highly touted Wolfram Image Identification Project misidentified the picture as a “badminton racket.”
Humans do not have to be shown a million wagons to know the difference between a wagon and a badminton racket. We know that the above image contains a box because of its similarity to other boxes we have seen and, virtually simultaneously, we recognize that the circles we see are wheels because they go below the bottom of the box, which we know will allow the box to be rolled on its wheels, and we recall seeing boxes rolled on wheels. We also reason that there are probably two more wheels on the other side of the box, even though we do not see them, because we know that the box wouldn’t be stable otherwise.
We have learned from experience that boxes with wheels are often used to carry things—so, this box is probably hollow with a space to carry stuff. Even though we cannot see inside the box, we wouldn’t be surprised if there is something in there—perhaps some toys, rocks, or kittens.
Even though it is drawn with just two lines, we know the handle is a handle because boxes with wheels usually have a handle or a motor, and the thing protruding out of the box resembles other handles we have seen attached to things that are pushed or pulled. We think that the text Red Devil is most likely unimportant decoration because words written on boxes are usually just decorative. In an instant, we know that this is a wagon, not a business or badminton racket.
Not only that, we know from experience what wagons can and cannot do. They can be lifted. They can be dropped. They can carry things. They can be pushed and pulled. They cannot fly or do somersaults. We don’t know this by matching pixels. We know it because we have seen boxes with wheels and handles and we know their capabilities, individually and collectively.
Our minds are continuously processing fleeting thoughts that come and go in a ceaseless flood of analogies. We might compare the Red Devil font to other fonts and compare the white color to similar colors. We might think of a sled, a movie with a sled, a sled ride. We might think of a car or a horse that can be ridden or used to carry things. Thoughts come and go so fast that we cannot consciously keep up. The flood is involuntary and would be overwhelming were our minds not so remarkable. We can even think about our thinking while we are thinking.
Do computers have this self-awareness? Can computers do anything remotely resembling our brains sifting through dozens, if not hundreds, of thoughts—holding on to some, letting some go, combining others—and having some thoughts lead to other thoughts and then other thoughts that are often only dimly related to our original thoughts?
Computers do not understand information—text, images, sounds—the way humans do. Software programs try to match specific inputs to specific things stored in the computer’s memory in order to generate specific outputs. Deviations in the details can cause software programs to fail. The crude depiction of the handle might be mistaken for a baseball bat or a telephone pole. The circular wheels might be mistaken for pies or bowling balls.
Our mind’s flexibility allows us to handle ambiguity easily and to go back and forth between the specific and the general. We recognize a specific wagon because we know what wagons generally look like. We know what wagons generally look like because we have seen specific wagons.
Humans understand the world in complex ways that allow us to speculate on the past and anticipate hypothetical consequences. We might surmise from a wagon’s crude construction that it was handmade and we might conclude from the absence of dents and scratches that it is new or, at least, well taken care of. We might predict that the wagon will fill with water if it rains, that it can be lifted by the handle, that it will roll if given a push. We might imagine that if two children play with the wagon, one child will climb inside and the other will pull it. We might expect the owner to be nearby. We can estimate how much it would cost to buy the wagon. We can imagine what it would be like to ride in it even if we have never ridden in a wagon in our lives. We know that it might be fun but dangerous to sit in a wagon at the top of a hill.
We are also able to recognize things we have never seen before, such as a tomato plant growing in a wagon, a wagon tied to a kangaroo’s back, an elephant swinging a wagon with its trunk. Humans can use the familiar to recognize the unfamiliar. Computers are a long way from being able to identify unfamiliar, indeed incongruous, images.
Recently, OpenAI publicized a neural network called CLIP which “efficiently learns visual concepts from natural language supervision.” Traditionally, visual classification programs match labels to images without making any attempt to understand what the label means. In fact, image categories are generally numbered because the label—like wagon—that goes with the category contains no useful information.
CLIP is said to be different because the program is trained on image-text pairs, with the idea being that the text will help the program identify an image. I tried out a free online version. The user uploads an image and types in proposed labels, at least one of which is correct. The program then shows its assessment of the probabilities of each label being correct. I tried it out with the wagon image and the proposed labels wagon, sign, and badminton racket based on my previous experience. The program seemed to want a fourth proposed label, so I added goalposts because I had just read an article about Liverpool’s disappointing season. CLIP favored sign (42%) and goalposts (42%), followed by badminton racket(9%) and wagon as the least likely label at 8%.
I wasn’t sure if goalposts was the best spelling so I replaced it with goal posts and CLIP’s probability of this being the correct label jumped from 42% to 80%! The sign label fell to 14% while badminton racket and wagon each came in at 3%. CLIP clearly did not understand the text labels in any meaningful sense, since goalposts and goal posts are just alternative spellings of an identical concept. CLIP seems to be a bit of trickery in that the main purpose of the labels is evidently to help the algorithm by narrowing down the possible answers. This is not particularly useful since, in most real-world applications, we won’t be able to give the program helpful hints, one of which is guaranteed to be correct. As I tell my students, life is not a multiple-choice test.
More generally, the program’s attraction to the labels goalposts and goal posts are convincing evidence that it is still just trying to match pixel patterns. No human would mistake this wagon image for goalposts.
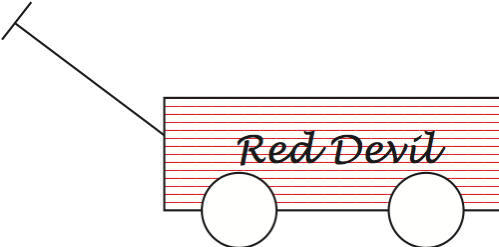
The low probabilities assigned to wagon were also interesting in that CLIP was no more successful in recognizing this image than were the other programs I tried. Perhaps the program is brittle because it was trained on red wagons and does not know what to make of a white wagon. I changed the color of the wagon to red and the wagon probability jumped to 77% with goalposts, and 69% with goal posts. Then I used a green wagon and the wagon probability dipped to 40% with goalposts, and 32% with goal posts. Finally, for the red-and-white striped wagon below, CLIP’s wagon probability was 7% with goalposts, and 2% with goal posts—which were even worse than for the white wagon.
Humans notice unusual colors, but our flexible, fluid mental categories can deal with color differences. For humans, the essence of a wagon is not its color. White wagons, red wagons, and red-and-white wagons are still wagons. Not so for a pixel-matching computer program.
The label artificial intelligence is an unfortunate misnomer. The ways in which computers process data are not at all the ways in which humans interact with the world, and the conclusions computers draw do not involve the wisdom, common sense, and critical thinking that are crucial components of human intelligence. Artificial unintelligence is more apt in that even the most advanced computer programs are artificial and not intelligent.