
Coronavirus: Is Data Mining Failing Its First Really Big Test?
Computers scanning thousands of paper don’t seem to be providing answers for COVID-19On March 16, 2020, the White House asked AI experts to mine 29,000 scholarly papers for data that might provide useful information to help fight the coronavirus pandemic (COVID-19). The collective tome was assembled with the help of Microsoft and Alphabet, the parent company of Google.
It’s unclear whether the AI powerhouses Microsoft and Deep Mind, another Alphabet company, tried cracking the problem themselves. Deep Mind was the developer of AlphaGo, the AI computer program that defeated the world champion in GO. Media lauded the success of AlphaGo as a potential solution to half the world’s problems.
A Deep Mind slogan is “What if solving one problem could unlock solutions to thousands more?” Think of the good will generated for Deep Mind if the company had successfully examined the 29,000 papers and found useful coronavirus information! The same for Microsoft. Having first access, both companies may have tried and failed. It could be that, after Microsoft and Deep Mind failed, the decision was made to pass the buck to give the rest of the world a chance.
That is conjecture on my part. But over a month has passed since public release and I see no report of any attempts, let alone success. Possibly, and most likely, there are no smoking guns in the papers for anyone to find.
Data mining has had its successes and failures. The most celebrated data mining program is IBM Watson, which beat the world champions in the quiz show JEOPARDY. At its disposal, IBM Watson had Wikipedia and more. Watson’s key strength was its speed. For the game of JEOPARDY, you or I could answer most of the prompts just as well as Watson if time were not a factor and we had access to the Google search engine.
Watson was subsequently lauded as a solution to many data mining problems. Indeed, the search engine Yippy.com is powered by IBM Watson. I like the page. I find Yippy.com often gives deeper, more informative, and less biased responses than a Google search.
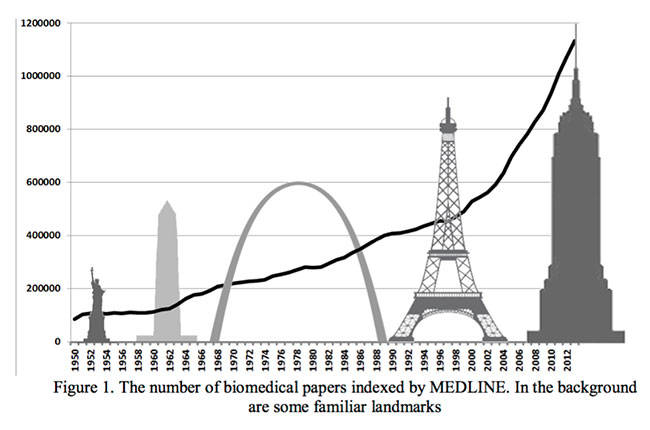
Medical care would be enhanced if physicians and surgeons could use IBM Watson to search for information relevant to specific cases. Fueled in part by the pressure on academics to publish, the volume of medical literature is currently riding an exponential curve. In 2016, I wrote a series of papers [1-6] that included a plot of the number of papers published on Medline each year. Medline lists all papers in life sciences, including biomedicine, from select journals. Because all medical journals are not included, the count is conservative. As seen in the figure below, the stack of Medline papers rivals the height of the Empire State Building in the plot [3]. No one can keep up with this volume of literature. But this should not be a problem for today’s computers. IBM Watson is said to read two million pages per minute.
Yet IBM Watson failed miserably at assisting doctors in mining medical literature and was fired by MD Anderson Cancer Center. The failure ranked #1 in Mind Matters News’s Top Ten Hype Stories of 2018.
The problems IBM Watson encountered still prevail with mining information about Covid-19. Roll Call headlines “AI researchers seeking COVID-19 answers face hurdles,” noting that “Reading and comprehending articles on coronavirus proves to be difficult for machine learning.” Hopefully, the effectiveness of the mining of medical literature will improve.
I see no reason why data mining might not some day help physicians. But the current quest to shoot for the moon seems to be a staircase being built one step at a time.

Note: The cartoon above is from xkcd and is Creative Commons.
{kind=link}
REFERENCES
- Robert J. Marks II “Everything You Ever Wanted to Know about Peer Review (and probably more),” TheBestSchools.org (May 2016) [Cache]
- Robert J. Marks II “Peer Review Pt. 1: The Way It Was,” TheBestSchools.org (May 2016) [Cache]
- Robert J. Marks II “Peer Review Pt. 2: The Sausage Factory,” TheBestSchools.org (May 2016) [Cache]
- Robert J. Marks II “Peer Review Pt. 3: Towers of Mostly Babble,” TheBestSchools.org (May 2016). [ Cache, Figure 1, Figure 2, and Figure 3]
- Robert J. Marks II “Peer Review Pt. 4: How To Publish Your Scholarly Paper,” TheBestSchools.org (May 2016) [Cache]
- Robert J. Marks II “Peer Review Pt. 5: Artificial Unintelligence: will journals accept papers written by a computer?,” TheBestSchools.org (May 2016) [Cache]
{kind=link}
{kind=link}
{kind=link}